The CentOS ISA SIG was created to have a place to experiment with architecture baselines, compiler optimizations, and other optimization techniques that could potentially benefit users of newer hardware on real-world workloads. We’ve been up and running for a while now, so we thought it would be interesting to describe what we’ve done, how it has played out so far, and how others interested could help. The SIG is always open to other participation and ideas and sees itself as a great place for collaboration on ISA implications in general.
x86-64-v2 vs x86-64-v3 Performance comparison testing
CentOS Stream 9 is built using the x86-64-v2 baseline today. Our first area of investigation was to take CentOS Stream 9 and rebuild it using x86-64-v3. For those not familiar with the x86-64 baselines, this Wikipedia article does a decent job of explaining the difference. The short version is that x86-64-v3 allows the compiler to assume the AVX/AVX2 instruction set is present on the hardware that will be used to run the resulting binaries. That in turn allows it to optimize certain code paths to take advantage of these vector instructions. The x86-64-v3 baseline is effectively most x86-64 CPUs that have been released since ~2015, and the definition of the levels is defined in the x86-PSABI project.
There were a few reasons we started with x86-64-v3. The first is that the current x86-64-v2 baseline is still limited to SSE instructions, which is circa 2009 era CPUs. One would naturally assume that CPU architectures and instruction sets have evolved significantly over the past 14 years. However, we also know that working hardware is often deployed long after the typical 3-year industry refresh cycle, and CentOS Stream users are likely to still have 2015 era machines. The next version of CentOS Stream is likely to stick with x86-64-v3, and we wanted to get some experience with this before it arrives. The second reason is that jumping to x86-64-v4, which introduces AVX-512, may indeed allow for further performance gains, but we’d be guessing where any gains came from. Using an incremental approach would hopefully inform us of the areas that are already capable of using vector instructions for gains, with an eye towards further optimization either via the compiler itself or future baseline investigations.
The Builds
To accomplish our testing, we needed to have a fairly static set of binaries to work from, and chasing an ever-evolving CentOS Stream 9 seemed counterproductive. So we settled on the following approach:
- Create two different buildroots, one for the existing v2 baseline and one for the v3 baseline (c9s_base and c9s_opt)
- Bump the system compiler to GCC 12, primarily to take advantage of the work that had gone into upstream GCC on auto-vectorization
- Set the default compiler flags to build for -march=x86-64-v2 and -march=x86-64-v3 in their respective buildroot
- Rebuild the vast majority of CentOS Stream 9 in each buildroot
- Perform performance testing
There were a few packages beyond gcc and redhat-rpm-config that had to be adjusted to build either with the newer GCC and/or the x86-64-v3 baseline, but most of the OS built just fine. The end result is two repositories, ISA Baseline (v2) and ISA Optimized (v3). As we said earlier, these are a snapshot of CentOS Stream 9 so that we have comparable versions for investigation. It’s important to note that they remain frozen and will not include any fixes or updates that have landed in the main CentOS Stream 9 repositories after they were created.
The Testing
Once the builds were available, we began performance testing to see what the results were. Our expectation was that we would see some gains in code that naturally lends itself to vectorization, such as compression or cryptography. In fact, we are not the first to have this hypothesis, and this article shows that it’s largely valid, though not without some caveats. With that in mind, we wanted to see if anything else benefited as well.
We settled on a subset of the Phoronix benchmark test suite. These were run on Ice Lake class Intel machines, and the comparison was done between v2 and v3. The results were fairly mixed, with some small percentage gains in certain benchmarks and a few minor regressions in some areas. Many of the Phoronix test suites build with -march=native during installation/compilation, so care was taken to ensure that the proper -march=x86-64-v2/-march=x86-64-v3 flag was passed to the tests themselves.
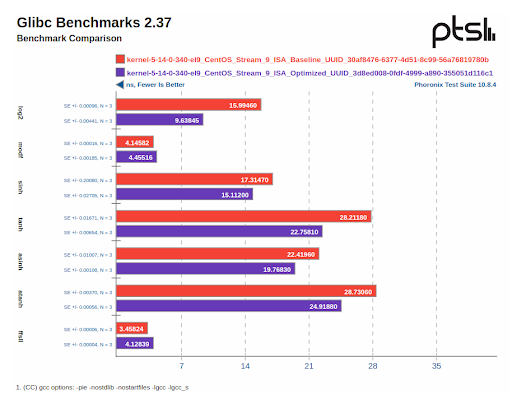
Some of the benchmarks, such as the glibc_bench, Mocassin, and John the Ripper (md5crypt) benchmarks saw significant results. Given that we changed both the compiler version and the baseline, we dug into which of those variables contributed the most impactful change to the results. For the latter two benchmarks, we saw a 2.2x speed up. Mocassin seems to benefit the most from the auto-vectorization that GCC12 does. Using GCC 11 with appropriate compiler flags produced similar results. The md5crypt benchmark benefits from the increased parallelism and double register width that AVX introduces over SSE. That was encouraging as it further confirms the hypothesis that workloads which lend themselves to vectorization can benefit greatly. Interestingly, we discovered that some of the upstream glibc math library functions lacked optimized IFUNC implementations. This is currently being investigated upstream to see if further IFUNC additions will result in similar gains for those areas.
Beyond that, we were left wondering what else would benefit from a newer baseline. We tried some AI frameworks, and found that most of them also self-optimize with -march=native or other similar techniques. There were some gains, but the results were very noisy and did not result in conclusive overall results. It is also worth noting that many AI workloads would see more performance gain from using hardware optimization, such as GPGPU acceleration or other dedicated hardware accelerators. That is outside the scope of the SIG for now though.
What next?
With our preliminary results showing gains in the areas we expect but not overwhelming performance across the board, one might wonder why that is and what comes next.
Taking a step back and thinking about this at a higher level, performance is always going to be dictated by the predominant code paths that the CPUs are executing. That code is going to be highly dependent on the workloads being run. For example, if a machine is primarily used as a database server, one would expect the DB code itself to be the main factor in where performance can be gained. The underlying OS will of course be important, but the CPU is likely spending most of the time executing DB code, and a highly tuned lower-level library isn’t going to sway the results much unless the DB is calling into that library frequently. Similar for something like a webserver. For application level workloads we provide as part of the OS, we can of course build them with the newer baseline and perhaps see gains. However, most of the applications that are run on top of CentOS Stream are built by the end user or an ISV.
This observation leaves us with a bit of a conundrum. We can tune the OS userspace, but if the applications aren’t tuned then does it matter? We think it can but it would be really interesting to see what other workloads lend themselves to optimization that we don’t really have insight into. One of the ideas we have is to provide some documentation on how to build end user applications with the newer baselines, or to provide some packages that a user could install and tweak the compiler defaults to take advantage of newer instructions.
This is where we’d love some input from interested users. If you have an application that you use regularly and are interested in seeing if it benefits from optimization, it would be great if you could use the ISA Optimized repository to build and run your application and provide some test results. We also have container images available for workloads that lend themselves to containerization. The more results we can gather on workloads that benefit from these baselines and techniques, the more ideas we’ll have on how to position CentOS Stream to provide the best performance we can. Results can be provided by filing an issue in the ISA SIG gitlab project.
In the meantime, there are some other areas that are worth looking into. The Hyperscaler SIG already has optimized versions of zlib that might be worth redoing/moving to the ISA SIG. Other OS-provided packages such as nginx or httpd might provide interesting targets as well. We’ll see what comes next!
Thanks for reading and feel free to reach out to the SIG if you’re interested.